
Die Function-Point-Methode orientiert sich an den Anwendungsfällen eines Systems und zählt Elementarprozesse, mit denen Daten über die Systemgrenzen hinweg ein- oder ausgegeben werden, sowie damit in Zusammenhang stehende Datenstrukturen in internen und externen Datenbeständen.
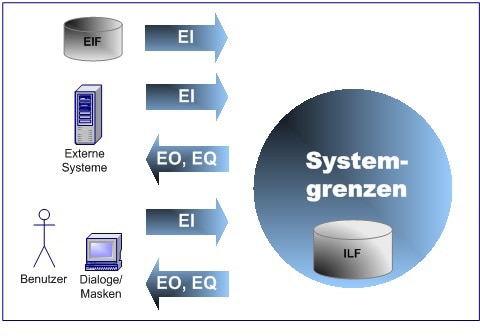
Die Herausforderung: Eine klassische Function-Point-Analyse setzt eine präzise und vollumfängliche Kenntnis der Anwendungsfunktionalität voraus, was, abhängig von der Systemgröße, aufwändig ist. Inzwischen existieren Ansätze für automatisierte Zählungen. Zwar ist auch hier eine genaue Kenntnis der den Elementarprozessen entsprechenden Codestrukturen und Namenskonventionen notwendig – dennoch lohnt der Implementierungsaufwand. Einmal eingerichtet, kann die Zählung nach jedem neuen Release oder Inkrement ohne großen Aufwand wiederholt werden.
Abstriche bei der Präzision
Ein genereller Nachteil der Function-Point-Methode: Punktwerte sind durch dreistufige, nach oben offene Intervallskalen festgelegt. Bei der Zählung von Datenbeständen (Datenstrukturen) ergeben sich die Punktwerte beispielsweise aus einem dreistufigen Intervall für die Anzahl ihrer Datenelemente und einem weiteren Intervall für die Anzahl der fachlichen Feldgruppen. Die Folge: Alle Datenstrukturen mit über 50 Elementen sowie mehr als einer Feldgruppe erhalten den gleichen Punktwert – ungeachtet der tatsächlichen Anzahl. Viele ältere Systeme zeichnen sich jedoch durch wenig strukturierte Datenmodelle, Schnittstellen mit extrem großen Satzstrukturen oder Masken mit einer sehr hohen Zahl an Elementen, die horizontal und vertikal verschoben werden müssen, aus. Damit korreliert der nach der Function-Point-Methode gemessene Umfang nicht wirklich mit der Menge der verarbeiteten Information.
Bis heute ist die Function-Point-Analyse weit verbreitet. Oft in Form von Näherungsverfahren wie Rapid. Diese verzichten komplett auf eine Komplexitätsbewertung und ersetzen die Intervallskalen durch Durchschnittswerte. Dies führt zu einem noch gröberen Ergebnis und deutlichen Einschränkungen bei der Vergleichbarkeit. Eine Unschärfe, die sich durch den Einsatz präziserer Messverfahren vermeiden lässt.
Wie sind Ihre Erfahrungen mit der Function-Point-Analyse und wo sehen Sie Alternativen? Vielleicht in der COSMIC-Methode? Diese stelle ich Ihnen in meinem nächsten Beitrag vor.
Bildquelle: Shutterstock



Dieser Beitrag hat 2 Kommentare
Ich halte diese Methode immer noch für die beste Möglichkeit, Aufwandschätzungen durchzuführen (sofern man sich eine eigene Wissensbasis aufgebaut hat) und sozusagen nebenbei die Größe der Software zu ermitteln. Ich sehe auch keine Alternative, um bestimmte KPIs zu ermitteln und ein internes (oder externes) Benchmark damit durchzuführen. In den letzten Jahren haben sich einige Firmen von dieser Methode getrennt, weil keine ausreichenden Argumente vorgelegt werden konnten und der hohe Zeitaufwand als KO-Kriterium gesehen wurde.
In welche Richtung geht es? Gibt es doch eine Alternative?
Bei der in diesem Beitrag beschriebenen Methode handelt es sich um die in den 70er Jahren definierte “klassische” Function-Point-Methode nach ISO/IEC 20926. Mit der ISO/IEC 14143 (“funktionsorientierte Umfangsmetriken”) entstand wenig später ein Industriestandard, auf dessen Grundlage weitere Messmethoden definiert wurden. Während der “Klassiker” Elementarprozesse und Datenstrukturen zählt, werden bei der COSMIC-Methode, die auch “Full Function Points-Methode” genannt wird, die beteiligten Datenelemente gezählt, was bei gleichem Messaufwand die Genauigkeit erhöht. Die PASS Data Interaction Point-Methode zählt ebenfalls Datenelemente, gewichtet diese zusätzlich entsprechend ihrer Verwendung, um der unterschiedlichen Komplexität Rechnung zu tragen. Diese alternativen Methoden haben sich für Aufwandsschätzungen und für KPIs bewährt und werden in diesem Blog jeweils durch eigene Beiträge kurz beschrieben. Der Trend geht eindeutig in Richtung automatisierter Messungen, was den Zeitaufwand reduzieren kann (siehe auch zu diesem Thema den entsprechenden Beitrag).